
As machine learning continues to revolutionize industries, Long Short-Term Memory (LSTM) networks stand out as a powerful tool for handling sequential data. If you’ve come across Stack Overflow threads or tutorials on LSTMs, you probably want an easy-to-understand explanation. Let’s explore the LSTM model, including its relevance and quirks in a way that feels approachable.
What Is an LSTM?
LSTMs are a kind of recurrent neural network (RNN) which excel at modeling sequences. Unlike standard neural networks which process fixed-sized input, LSTMs process dynamic data that unfolds over time. Consider time-series data, natural language, or even video frames—LSTMs shine in contexts where earlier information influences later decisions.
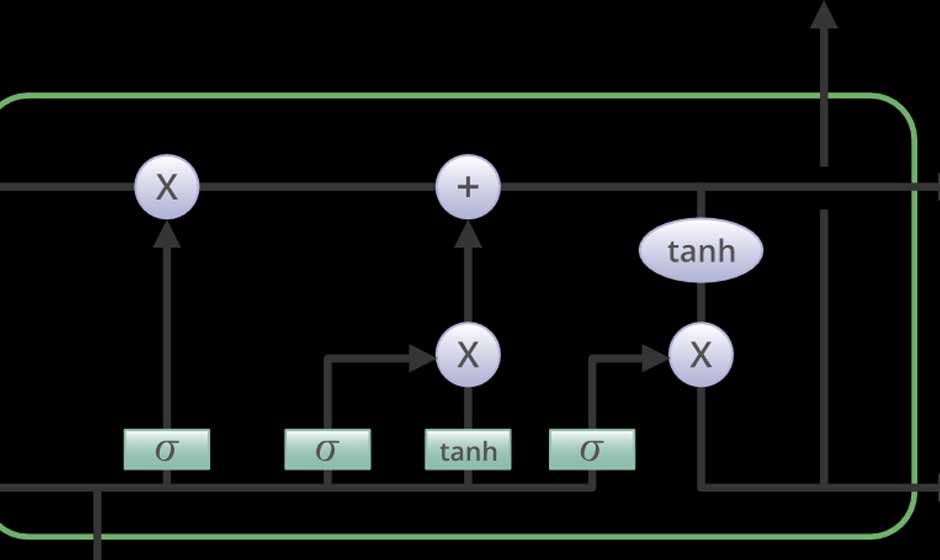
An LSTM stands out in remembering long-term dependencies without falling prey to the pitfalls of traditional RNNs like the vanishing gradient problem. This is achieved through the introduction of a system of gates—structures that control how information moves through the network.
How LSTMs Work: Breaking Down the Gates
In order to understanding LSTMs, it is helpful to focus on their three types of gates:
Forget Gate
This gate selects which data should be deleted from the cell state. It takes in the current input and the previous hidden state and uses sigmoid function to output a value between 0 – 1. Closer to 1 means “retain,” and closer to 0 means “forget.”
Input Gate
This gate determines what information should be added to the cell state. It has two parts: a sigmoid layer that selects values to update and a tanh layer that creates candidate values to add.
Output Gate
This output gate decides what part of the cell state becomes the output. This is filtered through a sigmoid function that ensures the network outputs correct information at each step.
The combination of these gates makes LSTMs capable of addressing short- and long-term dependencies effectively, making them an ideal solutions for tasks like text generation, stock market prediction, and speech recognition.
Why Developers Love (and Struggle With) LSTMs
LSTMs are a topic developers often discuss on Stack Overflow. LSTMs are vastly capable but can be a bit confusing to master. Questions like “Why is my LSTM not learning?” or “How do I tune hyperparameters for better performance?” are commonly asked on LSTM model Stack Overflow threads.
Here are a few relatable challenges developers often face:
Overfitting: LSTMs are robust but prone to overfitting on small datasets. Solutions discussed often involve regularization techniques like dropout or noise addition.
Vanishing or Exploding Gradients: LSTMs mitigate vanishing gradients better than vanilla RNNs but poor weight initialization can still be a problem.
Tuning Hyperparameters: Choosing the right number of layers, neurons, and batch sizes can feel like trial and error.
Conclusion: LSTM Model Stack Overflow
The LSTMs are the foundation of sequential data modeling and offer certain advantages to developers that spend some time on their mastery. While challenges like hyperparameter tuning and data preparation can be daunting, the supportive developer community ensures no question goes unanswered. LSTMs can unlock insights in sequential data with persistence and the right guidance to drive innovation across industries.